Google DeepMind หน่วยวิจัย AI เปิดตัว Gemini เวอร์ชั่น 1.0 เป็นโมเดลภาษาขนาดใหญ่ที่ทำงานในรูปแบบมัลติโมเดล เข้าใจทั้งรูปภาพ ข้อความในเชิงตรรกะเหตุผล วิดีโอ เสียง โค้ด ได้ภายในคราวเดียว
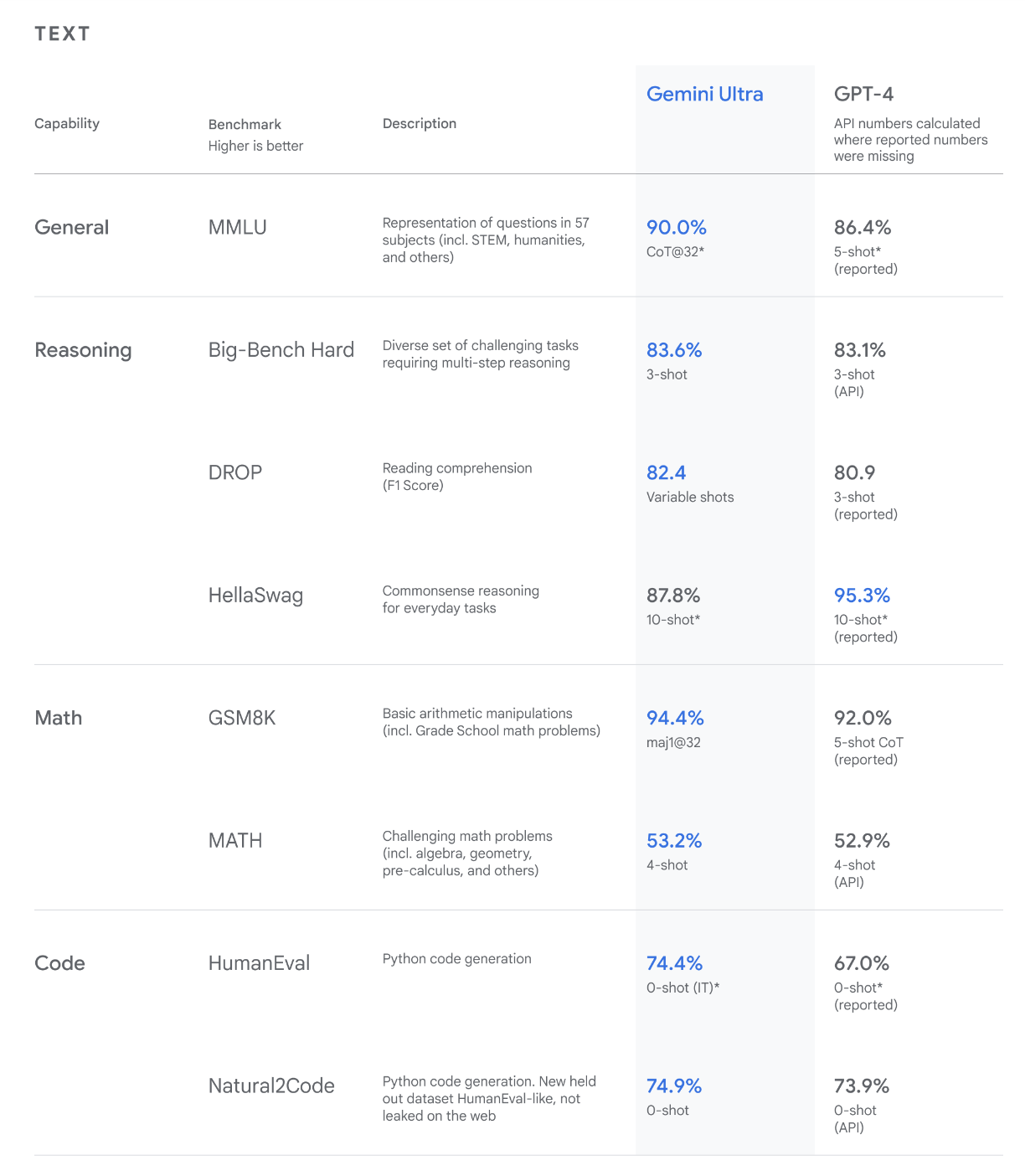
Google โชว์ผลความสามารถของ Gemini ว่าเป็นโมเดลแรก ที่ทำได้ดีกว่าผู้เชี่ยวชาญที่เป็นมนุษย์ใน MMLU (Massive Multitask Language Undering) ซึ่งเป็นหนึ่งในวิธีที่ได้รับความนิยมมากที่สุดในการทดสอบความรู้และความสามารถในการแก้ปัญหาของโมเดล AI และทำได้ดีกว่า GPT-4
Gemini มี 3 ขนาดคือ
- Gemini Nano รันในอุปกรณ์ Pixel 8 Pro เพิ่มความสามารถ AI ในมือถือไม่ว่าจะเป็น สรุปไฟล์เสียงที่ยืดยาว ซึ่งทำได้แม้ไม่มีเน็ต, Smart Reply ใน Gboard โดย AI ร่างคำตอบให้ก่อนกดส่ง
- Gemini Pro ให้คำตอบเร็วขึ้น นำไปเพิ่มความสามารถให้แชทบ็อท Bard ให้เป็นเวอร์ชั่นใหม่ๆ ทำความเข้าใจ การสรุป การใช้เหตุผล การเขียนโค้ด และการวางแผนที่ซับซ้อนขึ้น ไทยสามารถใช้งาน Gemini Pro ได้ แต่ยังรองรับเฉพาะภาษาอังกฤษ
- Gemini Ultra ถือเป็นโปรดักต์เรือธงที่ Google โชว์ว่าชนะ GPT-4 ในการทดสอบทุกด้าน เข้าในการทำงานหลายอย่างในครั้งเดียว และเข้าใจการทำงานซับซ้อน โดย Google จะนำ Gemini Ultra ไปเพิ่มความสามารถใน Bard Advanced ซึ่งคาดว่าจะเป็นแชทบ็อทพรีเมี่ยมแบบเสียเงิน เปิดตัวช่วงต้นปีหน้า โดยตอนนี้อยู่ระหว่างทดสอบความปลอดภัย
หากใครสนใจข้อมูลเชิงลึก ตามไปอ่านรายงานการทดสอบฉบับเต็มได้ที่ https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
.
ที่มา : https://blog.google/technology/ai/google-gemini-ai/#performance